
Hidden Patterns in Unstructured Data: Real Examples for Better Pricing Models
Pricing decisions separate successful businesses from struggling ones. Yet 80% of the information that could improve these critical choices sits unused in customer reviews, social media posts, and support conversations. Most companies focus exclusively on structured data—the neat rows and columns of traditional databases—while missing the deeper insights hidden in everyday customer interactions.
This gap creates real consequences. Research reveals that only 18% of organizations effectively use unstructured data despite its abundance. The missed opportunity grows larger when you consider that up to 90% of enterprise-generated data falls into the unstructured category.
Customer expectations make this oversight costly. Today’s buyers want personalized experiences—63% express interest in tailored recommendations, and the same percentage will share more information with companies that deliver exceptional service. Your pricing models need both the precision of structured data and the context that unstructured sources provide.
The businesses that crack this code gain significant advantages. Customer reviews reveal price sensitivity patterns that surveys miss. Social media conversations expose competitor positioning before it shows up in market reports. Support tickets highlight product value perceptions that drive willingness to pay. These signals exist in every industry—retail, energy, SaaS—waiting for the right techniques to extract them.
Throughout this article, you’ll see specific examples of how companies identify these hidden patterns and build pricing models that respond to real market signals rather than static historical data.
Understanding Unstructured Data in Pricing Contexts
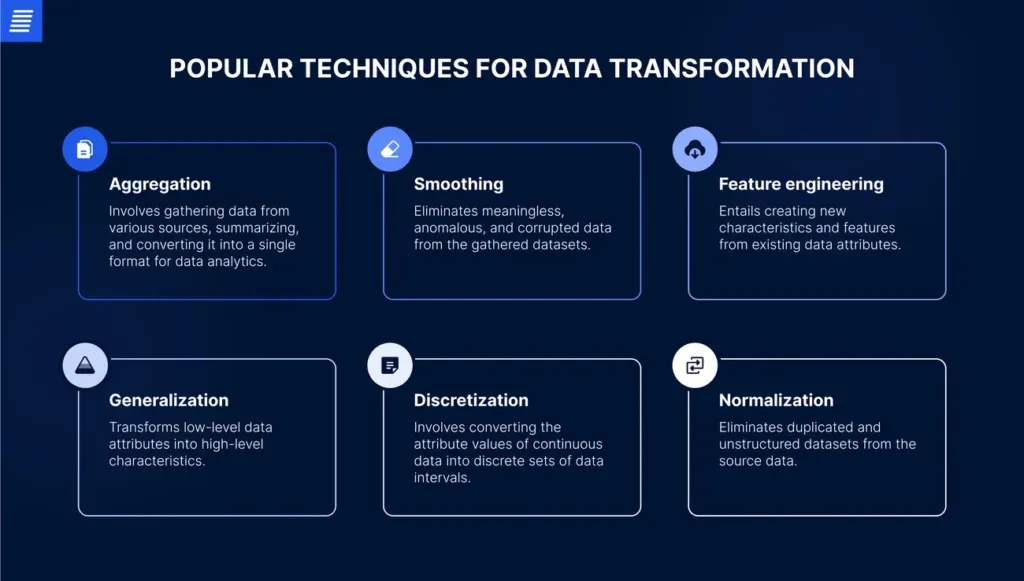
Image Source: EffectiveSoft
Effective pricing strategies demand both numbers and narratives. 80-90% of business data remains unstructured, yet most pricing models ignore this rich information source. The companies that master both structured databases and unstructured insights create pricing systems that adapt to real market conditions rather than historical averages.
Difference Between Structured and Unstructured Data in Pricing Models
Traditional pricing models rely on structured data—clean spreadsheets with product costs, transaction histories, and customer demographics organized in predictable rows and columns. This information flows easily into standard analytics tools and produces immediate insights through database queries.
Unstructured data operates differently.. Customer reviews, social media posts, and support conversations lack this organized framework. Processing these sources requires specialized techniques, but the effort reveals context that structured data cannot provide.
The impact on pricing decisions becomes clear when you consider these distinctions:
-
Processing Speed: Database queries deliver structured insights instantly, while unstructured analysis requires natural language processing and machine learning tools.
-
Information Depth: Structured data tells you what customers bought and when, while unstructured sources explain why they chose your product over competitors..
-
Resource Allocation: Most analytical resources focus on the 20% of data that’s structured, leaving the majority of available insights unexplored].
Modern pricing strategies must combine both approaches. Value-driven shoppers make up 41% of consumers worldwide, and these customers base decisions on factors that only unstructured data reveals—product reviews, social proof, and brand perception.
Examples of Unstructured Data in Retail and Energy Markets
Retail companies extract pricing intelligence from unexpected sources. Customer reviews provide direct feedback that influences pricing decisions. When reviews consistently mention that clothing “runs small,” smart retailers adjust product descriptions and pricing to reflect the true value customers receive, reducing returns and increasing satisfaction.
Energy markets demonstrate more sophisticated applications:
The Baidu search index now feeds into carbon price forecasting models. By tracking public interest in environmental topics, analysts predict market movements before traditional indicators signal change. Meanwhile, oil and gas companies face a different challenge—engineers spend 80% of their time searching for data that already exists within their organizations.
Smart retail environments generate continuous unstructured data streams through social media feeds, multimedia content, call center recordings, and in-store sensors. These sources provide real-time feedback on price perception, competitive positioning, and product satisfaction that traditional analytics miss.
Challenges in Extracting Pricing Signals from Unstructured Sources
Text-heavy, ambiguous data creates processing challenges that specialized tools must address. Organizations encounter specific obstacles that standard analytics cannot overcome.
Volume overwhelms traditional systems first. Half of all retailers watch their data volume double every five years. Storage infrastructure struggles to keep pace, and processing capabilities lag even further behind.
Context presents the second major hurdle. Simple keyword searches fail to capture intent or meaning, particularly for complex queries like “the most mature source rock in the Delaware Basin”. Surface-level analysis misses the nuanced insights that drive pricing decisions.
Data quality varies dramatically across unstructured sources, introducing potential inaccuracies into pricing models. Social media posts, customer reviews, and support tickets require different validation approaches, demanding significant cleanup resources.
The circular dependency problem creates additional complexity: AI models need relevant data points to optimize performance, yet identifying these relevant points requires analyzing unstructured content with optimized AI models.
Purpose-built systems must bridge the gap between raw unstructured text and AI-ready inputs. The companies that solve these processing challenges unlock pricing insights that competitors cannot access.
Feature Engineering from Unstructured Data Sources
Image Source: AltexSoft
Converting raw customer feedback into pricing intelligence requires systematic feature engineering. The gap between “customer says product is overpriced” and actionable pricing adjustments closes when you transform text into numerical features that algorithms can process.
Sentiment Scores from Customer Reviews and Social Media
Customer sentiment directly impacts pricing power. When multiple reviews mention “expensive but worth it,” that signals different pricing flexibility than “overpriced for what you get.” AI-powered sentiment analysis captures these nuances by preprocessing text data, removing noise like special characters and spam content, then evaluating emotional tone through machine learning models.
The output becomes immediately actionable. Sentiment scores typically range from -1 to +1, making them perfect inputs for pricing models. Businesses tracking sentiment alongside churn rates discover which price points trigger negative reactions before they impact revenue. Advanced systems detect specific emotions—frustration often precedes cancellation, while delight correlates with price acceptance.
Market research confirms the connection between sentiment and financial outcomes. Social media sentiment analysis achieves prediction accuracy exceeding 50% for stock market movements, with emotions like “fear” and “trust” serving as particularly strong indicators.
Keyword Extraction using TF-IDF and NLP
Pricing discussions contain specific language patterns that reveal customer value perceptions. TF-IDF (Term Frequency-Inverse Document Frequency) identifies these crucial phrases by measuring each term’s importance relative to the entire conversation set. Words that appear frequently in individual reviews but rarely across all reviews often highlight unique value drivers or pain points.
The process works through systematic steps:
● Preprocessing removes common words and standardizes text through tokenization and lemmatization ● Computing frequency measures how often terms appear within documents and across the corpus
● Ranking by TF-IDF scores reveals the most distinctive keywords
This technique serves multiple pricing applications—text classification, customer segmentation, and competitive analysis. Terms with high TF-IDF scores guide pricing strategy by highlighting what customers emphasize most when discussing value.
Combining Structured and Unstructured Features for Model Input
Pricing models perform best when structured transaction data meets unstructured customer feedback. Instead of choosing between numerical precision and contextual depth, successful implementations combine both data types through embedding techniques that convert text into numerical vectors.
Clustering approaches offer practical advantages over traditional dimensionality reduction. KMeans clustering computes distances between text embeddings and cluster centroids, creating fixed feature counts while maintaining interpretability. This method allows explicit control over feature numbers and reveals which customer comments define each cluster.
Real applications demonstrate the power of this hybrid approach. Car pricing models that process both structured specifications and unstructured descriptions simultaneously outperform single-source alternatives. One processing branch handles tabular data through connected layers, while another uses attention mechanisms to model relationships between specifications and customer descriptions. The combined predictions prove more accurate than either data type alone.
Modeling Techniques for Pattern Discovery
Image Source: Your Free Templates
Raw pricing data arrives messy, incomplete, and filled with noise that masks profitable patterns. The techniques that separate industry leaders from followers are those that can extract clear signals from this chaos while maintaining computational efficiency.
Wavelet Decomposition and CEEMDAN for Signal Denoising
Price volatility creates a persistent challenge: distinguishing meaningful market movements from random fluctuations. Wavelet denoising solves this by preserving sudden price changes while filtering out background noise—something Fourier-based methods cannot achieve.
The mathematics work in your favor. Wavelet transforms concentrate genuine price signals into a few large-magnitude coefficients, allowing you to eliminate smaller, noise-driven coefficients without losing critical information.
Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) handles the non-linear, unpredictable nature of pricing data:
-
Breaks complex price series into intrinsic mode functions based on local market behavior
-
Eliminates mode mixing issues through paired positive and negative noise addition
-
Converts chaotic signals into linear, predictable patterns for modeling
Hybrid Models: Random Forest + LSTM for Time Series
Single algorithms miss critical relationships that hybrid approaches capture. The Random Forest + LSTM combination delivers superior results by addressing different aspects of the prediction challenge:
-
Random Forest screens unstructured data features, identifying the most predictive elements
-
LSTM networks process these selected features through sequential learning algorithms
-
A meta-model combines both predictions for final output
This structured approach prevents overfitting while significantly boosting accuracy. One ensemble framework integrating ARIMA, Random Forest, and LSTM achieved impressively high R² scores ranging from 0.9304 to 0.9601 across multiple stocks.
Support Vector Regression for Mixed Data Inputs
Pricing models often struggle with the mixed nature of business data—numerical transactions alongside textual customer feedback. Support Vector Regression (SVR) excels here by creating tolerance margins rather than forcing exact fits, making it robust against outliers and noise.
SVR’s kernel functions transform data into higher dimensions where complex relationships become manageable. This versatility proves ideal for pricing applications that blend structured transaction data with unstructured customer sentiment.
Research confirms SVR’s practical value. Studies exploring SVR for S&P 500 index call options showed promising results compared to traditional parametric models, while other research demonstrates strong predictive power across various market segments when models receive periodic updates.
Real-World Examples of Unstructured Data in Pricing Models
Smart companies already use unstructured data to gain pricing advantages over competitors who stick to traditional approaches. These implementations show how businesses extract profitable insights from customer conversations, search behavior, and social media activity.
Baidu Index for Carbon Price Forecasting
The Baidu search index captures public sentiment that traditional carbon pricing models miss entirely. Researchers track daily search volumes for terms like “carbon neutrality,” “carbon trading,” and “low-carbon economy” to measure investor attention and market sentiment. This data serves as a proxy for carbon allowance demand, directly influencing price movements.
The results speak clearly. Models incorporating search data alongside traditional metrics deliver significantly better prediction accuracy than conventional approaches. Public interest intensity, measured through search behavior, enriches the information available to traders and enhances model explanatory power. Carbon markets now benefit from this early warning system that captures sentiment shifts before they appear in price data.
Social Media Signals in Airline Ticket Pricing
Airlines push personalization to new levels through social media analysis. Delta Air Lines implements AI-driven pricing across one-fifth of their domestic flights, officially analyzing booking patterns, destinations, and weather data. Yet 20 airlines worldwide explore broader AI pricing technologies that potentially incorporate social media activity, browsing history, and financial status indicators.
This creates a pricing reality where identical flights show different prices to different customers based on their digital footprints. Privacy advocates raise concerns, but airlines see competitive advantages. Two travelers booking the same flight simultaneously might pay vastly different amounts depending on their online behavior patterns.
Customer Reviews in Ecommerce Dynamic Pricing
Reviews drive pricing decisions in ways most retailers underestimate. With 88% of customers consulting reviews before purchases, these unstructured data sources directly impact willingness to pay. High-quality product sellers adjust prices based on review sentiment, capturing value that reflects customer perceptions.
Counter-intuitively, premium products often start with lower prices to accelerate review accumulation—a strategy called “reputation-riding”. Early reviews provide information diffusion value that outweighs immediate revenue losses. Once review profiles mature, sellers typically raise prices while sometimes reducing quality levels. This tension between short-term revenue and long-term reputation creates dynamic pricing opportunities that reviews make possible.
Interpretability and Evaluation of Pricing Models
Building sophisticated models means nothing if you can’t trust their decisions or explain their behavior to stakeholders. When your pricing models incorporate diverse data sources—structured transaction records alongside unstructured customer sentiment—evaluation becomes both more critical and more complex.
Monte Carlo Uncertainty Analysis for Model Trust
Monte Carlo simulation turns pricing uncertainty into quantified risk assessment through repeated random sampling, replacing fixed inputs with probability distributions to model uncertainty. This computational algorithm runs thousands of simulations to produce a range of likely outcomes with associated probabilities. For carbon price forecasting, Monte Carlo uncertainty analysis offers valuable insights into model interpretability.
The power lies in what this reveals about your pricing decisions. Rather than a single price recommendation, you see the full range of possibilities—expected outcomes alongside worst-case scenarios—enabling more informed, data-driven choices. This transparency builds confidence among executives who need to understand not just what the model recommends, but why.
Multi-step Forecasting Accuracy with Unstructured Inputs
Testing how well your models perform across different time horizons becomes crucial when unstructured data feeds your pricing decisions. Time series cross-validation preserves the ordered nature of data while testing predictions across multiple future points. Unlike traditional metrics, this approach maintains independence between sub-samples while assessing how model performance changes at different forecast horizons.
This matters because unstructured data—customer sentiment, social media trends, review patterns—may predict short-term price movements differently than long-term market shifts. Understanding these performance differences helps you adjust pricing strategies accordingly.
Feature Importance Analysis in Hybrid Models
SHAP (SHapley additive exPlanations) measures feature contribution in pricing models by calculating each variable’s average marginal contribution. This technique assigns importance values based on an additive attribution method that satisfies theoretical properties including local accuracy and consistency. Alternatively, permutation importance measures the increase in prediction error after shuffling a feature’s values.
These techniques answer the critical business question: which unstructured data sources most significantly impact your pricing model’s performance? When customer review sentiment scores consistently rank higher than traditional demographic data, you know where to focus your data collection efforts. When social media mentions suddenly become more predictive than historical sales patterns, you can adjust your monitoring systems accordingly.
The goal isn’t just accurate predictions—it’s building pricing models that business leaders can understand, trust, and act upon with confidence.
Conclusion
Your pricing models can become significantly more powerful when they incorporate the full spectrum of available data. The techniques explored here—sentiment analysis, keyword extraction, advanced modeling approaches—represent proven methods for extracting value from information sources that most competitors ignore.
The practical applications speak for themselves. Companies using search trends for carbon price forecasting achieve better prediction accuracy. Airlines analyzing social media signals create more targeted pricing strategies. E-commerce businesses adjusting prices based on review sentiment see improved customer satisfaction and retention.
The evaluation methods we’ve covered—Monte Carlo analysis, multi-step forecasting, feature importance techniques—ensure your models remain trustworthy as they become more sophisticated. Business leaders need confidence in their pricing decisions, especially when those decisions incorporate complex data sources.
Success requires both the right technical approach and strategic commitment. The businesses that excel will be those that view unstructured data not as a challenge to overcome, but as a competitive asset to exploit. Your customer conversations, review feedback, and social media mentions contain pricing intelligence that traditional approaches miss entirely.
The opportunity exists now. While competitors struggle with basic structured data analysis, you can build pricing models that anticipate market shifts, respond to customer sentiment changes, and identify profit opportunities before they become obvious to others.
At AI Profit Pulse, we help businesses identify these opportunities through our free pricing audit. This assessment reveals specific ways unstructured data can improve your current pricing strategies and highlights the patterns already hidden within your customer interactions.
The companies that master these techniques will set prices that customers accept, competitors struggle to match, and markets reward with sustained profitability.
Key Takeaways
Unstructured data represents 80-90% of business information yet remains largely untapped for pricing optimization. These insights reveal how to transform hidden patterns into competitive pricing advantages.
• Combine structured and unstructured data sources - Integrate customer reviews, social media sentiment, and search trends with traditional metrics for 50%+ improved prediction accuracy
• Apply advanced feature engineering techniques - Use TF-IDF keyword extraction and sentiment analysis to convert text into quantifiable pricing signals that models can process
• Leverage hybrid modeling approaches - Combine Random Forest feature selection with LSTM temporal learning and wavelet denoising for superior pattern recognition in complex datasets
• Implement real-time market intelligence - Monitor social media signals, search indices, and customer feedback to enable dynamic pricing that responds to market sentiment shifts
• Ensure model interpretability and trust - Use Monte Carlo uncertainty analysis and SHAP feature importance to maintain transparency while handling complex unstructured inputs The organizations that master unstructured data analysis will develop pricing models that anticipate market changes rather than simply react to them, creating sustainable competitive advantages through deeper customer understanding and more responsive pricing strategies.